목차
- 프로그램 (코드) 의 실행 원리
1-1 병렬 실행을 해보자.
1-2. GIL - 변수
2-1.isvs==
2-2. Global 예약어 - 반복형과 반복자
3-1. List
3-2. Tuple
3-3. 반복자
3-4. 제네레이터 - 사전
- 참조
0. 개요
선린인터넷고등학교 파이썬 강의를 위해 준비한 자료입니다.
그 동안 파이썬을 써오면서 들었던 의문에 답하기 위해 노력했습니다.
왜 GIL 이 존재할까?
왜 리스트 대신 튜플을 사용해야 할까?
결국엔 모두 0, 1 로 이뤄졌는데 왜 리스트는 사전의 키가 될 수 없을까?
1. 프로그램 (코드) 실행 원리
컴퓨터를 구성하는 요소로서 연상 장치, 기억 장치, 그리고 각 장치를 연결하는 연결 장치, 이 세 가지로 분류할 수 있다.
폰 노이만 구조 시스템에서 명령-실행 사이클은 메모리에서 명령을 가져온 다음 해독하고 실행한 결과를 메모리에 저장한다.
이때 명령에 필요한 데이터 (피연산자) 또한 메모리에서 읽어온다.
따라서 운영체제에게 프로그램 실행을 요청하면 프로그램을 메모리에 적재하는데 이를 프로세스라고 부른다.
단순히 코드만 적재되는 것이 아닌 스택, 힙 , 데이터 세그먼트, 쓰레드 등이 할당된다.
쓰레드는 실행 문맥 (Thread of context) 으로 CPU 가 명령을 실행시키는 데 필요한 모든 정보를 가지고 있는 객체다.
기본적으로 한 프로세스에는 하나의 쓰레드가 존재한다. 하지만 원한다면 쓰레드 객체를 추가해서 프로세스를 병렬로 실행할 수 있다.
또한, 쓰레드끼리는 프로세스의 메모리를 공유한다.
PS
메모리라고 말하면 흔히들 RAM 만 생각하지만 CPU 의 L1/L2 캐시도 존재한다.
만약 CPU 가 필요로 하는 데이터가 캐시에 존재하면 캐시에서 읽어오게 되고 없는 경우는 RAM 에서 데이터를 가져와 캐시에 갱신한다.
RAM 에서 데이터를 가져오는 것보다 캐시에서 가져오는 것이 훨씬 빠르기 때문에 캐시 적중률이 높을수록 속도가 빠르다.
1-1 병렬 실행을 해보자.
>>> import time
>>> from threading import Thread
>>> COUNT = 30000000
>>> def countdown(n):
... while n>0:
... n -= 1
...
>>> start = time.time()
>>> countdown(COUNT)
>>> end = time.time()
>>> end - start
?
위의 코드는 싱글 쓰레드로 삼천만 번 빼기 연산을 하는 코드다. 실행을 통해 몇 초가 걸렸는지 확인해보자. 그다지 빠른 속도는 아닌 것 같다. 두 쓰레드 객체를 띄어서 각각 천오백만 번씩 병렬로 빼기 연산을 하면 더 빨라지지 않을까?
>>> import time
>>> from threading import Thread
>>> COUNT = 30000000
>>> def countdown(n):
... while n>0:
... n -= 1
...
>>> t1 = Thread(target=countdown, args=(COUNT//2,))
>>> t2 = Thread(target=countdown, args=(COUNT//2,))
>>> start = time.time()
>>> t1.start()
>>> t2.start()
>>> t1.join()
>>> t2.join()
>>> end = time.time()
>>> end - start
?
결과를 확인해보자. 뭔가 이상하다.
1-2 GIL (Global interpreter lock)
방금의 코드는 왜 쓰레드를 하나 사용하는 것보다 느릴까? 그 이유는 GIL 때문이다. GIL 은 한 번에 한 쓰레드만 파이썬 프로세스를 실행하도록 전역적인 락을 거는 것이다. 그래서 단일 파이썬 프로세스는 병렬로 실행될 수 없다.
쓰레드 두 개로 실행한 방법이 더 오래 걸리는 이유는 중간 중간 쓰레드를 변경하는 컨텍스트 스위칭이 발생하기 때문이다.
Q. GIL 이 왜 존재하는걸까?
- CPython 인터프리터는 쓰레드 안전하지 않다.
- 구현상의 간편함. (가변형에 락 필요, 원자성 보장)
- 싱글 스레드 프로그램의 경우 GIL 이 더 빠르다.
Q. 쓰레드 안전하지 않은게 무엇인가?
여러 쓰레드가 동시에 실행됐을 때 올바르게 동작하지 않는 코드를 의미한다.
여러 쓰레드가 공유 자원에 대해 동시에 접근하면 여러 가지 문제가 생기게 된다.
대표적으로 check-and-act 문제가 있다.
if (x == 5)
x *= 5
한 쓰레드가 해당 조건문을 통과해서 x 에 5를 곱할 때 x 는 5가 아닐 수도 있다. 조건문을 통과하고 5를 곱하려는 시점에 다른 쓰레드가 5의 값을 변경할 수 있기 때문이다.
Q. 어떤 부분에서 CPython 인터프리터가 쓰레드 안전하지 않은가?
CPython 은 메모리 관리 기법으로 레퍼런스 카운팅 방식을 이용한다.
객체를 참조하는 변수의 숫자를 세고 그 숫자가 0이 되었을 때 객체를 해제하는 방법이다.
만약 변수의 참조를 올리고 내리는 연산이 병렬로 실행되면 다음과 같은 상황이 발생 가능하다.
내리는 요청이 올리는 요청 보다 조금 더 빨리 실행되어 객체는 이미 사라졌지만 올리는 요청을 한 변수는 사라짐을 감지하지 못하기 때문에 사라진 객체의 메모리 위치를 계속 가리키고 있는 뎅글링 포인터가 될 수 있다.
Q. 그럼 왜 파이선에 스레드 모듈이 존재하지?
병렬은 불가능 하지만 동시성은 가능하기 때문이다.
동시성은 스케쥴링이라고 이해하면 되는데 여러 쓰레드가 번갈아 가면서 실행되는 것이다.
대표적으로 I/O Blocking 이 발생했을 때 응답을 기다리는 동안 다른 스레드 객체를 사용할 수 있다.
Q. 병렬 실행이 불가능한데 왜 락이 존재할까?
우선 I/O Blocking 이 발생하지 않아도 쓰레드는 스케쥴링된다.
정확히 말하면 100 번의 명령 (어셈 코드) 마다 GIL 을 해제하는데 이 때 다시 락을 잡는 쓰레드가 실행된다.
여기서 문제는 연산 도중에 쓰레드가 멈추고 다른 쓰레드가 실행될 수 있다는 점이다.
이를 연산이 원자성을 보장하지 않는다고 한다.
실제 사례로 확인해보자.
>>> from threading import Thread
>>> count = 10000000
>>> def countdown(n):
... global count
... for i in range(n):
... count -= 1
>>> t1 = Thread(target=countdown, args=(count//2,))
>>> t2 = Thread(target=countdown, args=(count//2,))
>>> t1.start()
>>> t2.start()
>>> t1.join()
>>> t2.join()
>>> print(count)
?
위의 코드는 두 개의 쓰레드가 전역변수 (공유 변수) count 를 절반씩 내리고 있다.
따라서 count 의 결과 값으로 0이 찍혀야 할 것 같다.
결과는 어떨까? 항상 다르다.
마이너스 연산 과정은 다음과 같다.
- count 값 로딩
- count -1
- 연산 결과를 count 에 저장
t1 이 가져온 count 값이 10 이라면 count -1 을 해서 9 를 count 에 저장할 것이다.
근데 값을 저장하기전에 t2 로 쓰레드가 스위칭되면 어떻게 될까?
t2 도 10 을 가져와 9 를 저장한다. 계속 t2 가 실행되서 count 가 5 가 된 상태인데
다시 t1 이 실행되면 count 는 9 가 된다.
이런 식으로 종종 연산이 먹통이 된다.
2. 변수
컴퓨터에서 비유는 메커니즘을 더 명확하게 인식하게 해주는데 도움을 준다.
흔히들 변수를 상자로 비유하지만 변수는 포스트잇 (레이블) 로 생각하는게 더 좋다.
>>> a = [1,2,3]
>>> b = a
>>> a.append(4)
>>> b
[1,2,3,4]
(전문가를 위한 파이썬 8.1 변수는 상자가 아니다의 예제)
여기서 수 a, b 는 상자가 아니다. 리스트 [1, 2, 3] 을 가리키는 레이블 (포인터) 이다.
그렇기 때문에 a 로 append 를 해도 b 에 수정이 반영된다.
변수는 상자가 아니기 때문에 변수 a 에 리스트 [1, 2, 3] 을 할당했다는 말은 올바르지 않다.
사실은 변수 a 가 리스트 [1, 2, 3] 에 할당되었다는게 올바른 표현이다.
>>> def modify_list(var)
... var = [3,2,1]
...
>>> list1 = [1,2,3]
>>> modify_list(list1)
>>> list1
[1, 2, 3]
변수 x 가 객체에 할당되었다고 생각하는게 더 낫다는 것을 보여주는 좋은 예다.
리스트 [1,2,3] 에 할당되어있던 var 가 [3,2,1] 에 할당된 것이다.
그래서 list1 은 전혀 변경되지 않는다.
위에 코드에서 어떤 일이 발생했는지 살펴보자.
파이썬은 매개변수에 객체의 주소를 넘기는 call by object 방식을 사용한다.
call by sharing, call by object reference 라고도 말한다.
즉, var 는 list1 변수의 주소 값을 가진게 아니고 리스트 [1,2,3] 의 주소를 가진다.
이 상태에서 var = [3,2,1] 한다고 리스트 [1,2,3] 이 변경되는 것 또한 아니다.
리스트 [3,2,1] 이 생성되고 var 가 리스트 [3,2,1] 을 가리키게 된다.
이런 메커니즘의 결과로 함수는 전달받은 가변 객체를 변경할 수 있지만, 객체의 정체성 자체를 변경할 수는 없다.
2-1 is vs ==
is 연산자는 객체의 정체성을 비교 즉, 동일성을 검사한다.
반면 == 연산자는 객체의 값을 비교 즉, 동치성을 검사한다.
정체정보다 값을 비교하는 경우가 많기 때문에 여러분은 is 보다 == 연산자를 자주 볼 수 있다.
is 연산자는 싱글턴과 비교할 때 주로 사용되는데 변수를 None 비교하는 경우가 일반적이다.
>>> x = None
>>> x is None
True
>>> x = 1
>>> x is not None
True
is 연산자는 두 객체의 id 를 비교하기 때문에 == 연산자보다 빠르게 동작한다.
그래서 None == None 도 True 를 반환하지만 is 연산자를 사용한다고 한다.
그렇다면 속도를 무시하면 모든 연산에 == 연산자를 사용해도 되는걸까?
속도를 무시해도 변수가 정확히 None 임을 확인하고 싶다면 == 연산자를 사용해선 안된다.
그 이유는 is 연산자는 오버라이딩이 불가능하지만 == 연산자는 오버라이딩이 가능하기 때문이다.
다음과 같은 클래스를 작성해서 None 이 아니지만 x == None 이 참이 되게 할 수 있다.
>>> class A:
>>> def __eq__(self, other):
>>> return True
>>> A() == None
True
2-2 Global 예약어
>>> count = 1
>>> def count_up():
... count = count + 1
...
>>> count_up()
위의 코드를 실행하면 UnboundLocalError: local variable 'count' referenced before assignment 에러가 발생한다.
처음에 이 에러를 보고 신선한 충격에 빠졌다. 인터프리터는 소스 코드를 컴파일 하지 않고 한 문씩 해석하며 바로 실행하니까 우변을 평가하는 시점에 count 는 전역변수를 사용해 우변 결과는 은 2 가 되고 지역변수 count 에 2 가 저장돼 전역변수 count 는 변경 되지 않을 것이라고 예측했는데 에러가 발생했기 때문이다.
여러분도 본인 논리에 따라 어떻게 동작해야할 것 같은지 추측해보고 왜 에러가 발생했는지 생각해보자.
에러가 발생하는 이유는 인터프리터도 코드를 전처리하기 때문이다. 여러분이 함수를 선언하면 파이썬 인터프리터는 함수에 대한 정보를 미리 분석한다. 정보를 분석할 때 함수안에서 어떤 지역변수가 사용되는지 조사하고 이를 바탕으로 함수가 호출될 때 분석한 만큼 스택을 늘린다.
만약 관심이 있다면 만들면서 배우는 인터프리터 를 읽어보기 추천한다. 언어에 대한 감각이 생기고 위에서 말한 내용이 몸으로 체감이 된다.
Global 키워드는 이런 문제를 막기 위한 예약어다. 파이썬 프로세스에게 해당 변수는 전역변수로 사용할 것이라고 알려준다.
>>> count = 1
>>> def count_up():
... global count
... count = count + 1
...
>>> count_up()
>>> count
2
3. 반복형과 반복자
3-1 List
가장 잘 알려진 시퀀스로 List 가 있다.
해당 시퀀스는 공간이 모자라면 크기를 확장하는 동적 배열로 구현 되어있다.
배열을 한 번 확장할 때 여유 공간을 두고 확장 시킨다. 그리고 확장이 발생되면 새로운 리스트를 만들기 때문에 O(n) 이 소요된다.
가장 뒤에 아이템을 추가하는 Append 는 O(1) 이지만 랜덤 삽입은 삽입하고 나머지 배열의 데이터를 뒤로 옮겨야하기 때문에 O(n) 이 소요된다.
따라서 랜덤 삽입, 랜덤 삭제가 빈번한 경우 링크드리스트를 사용하는게 좋다고들 말한다.
하지만 이는 사실이 아니다. 현대 컴퓨터는 배열에 유리하게 진화되었다. 링크드리스트의 랜덤 삽입, 삭제가 O(1) 여도 O(n) 인 배열이 더 빠르게 동작한다는 분석이 있다.
https://dzone.com/articles/performance-of-array-vs-linked-list-on-modern-comp
리스트는 서로 다른 자료형을 담을 수 있는 컨테이너 시퀀스기 때문에 객체의 참조를 담고 있다.
반면 하나의 자료형만 저장하는 균일 시퀀스는 객체 참조 대신 자신의 메모리 공간에 각 값들을 저장한다.
따라서 균일 시퀀스가 메모리를 더 적게 사용하지만 문자, 바이트, 숫자 같은 기본적인 자료형만 저장 가능하다.
대표적인 균일 시퀀스로 array 가 있다. 따라서 문자, 숫자 같은 기본 자료형을 천만개 이상 저장할 경우 배열이 리스트 보다 훨씬 더 효율적이다.
>>> [i for i in range(5)]
[0,1,2,3,4]
>>> [i * 2 for i in range(5)]
[0,2,4,6,8]
>>> [i for i in range(5) if x % 2 == 0]
[0,2,4]
다음과 같은 편리 표현식으로 리스트를 만들 수도 있다. (리스트 컴프리헨션)
3-2 Tuple
튜플은 크기와 내용을 변경할 수 없는 불변성을 가진 리스트다.
리스트와 다르게 여유 공간을 둘 필요가 없어서 리스트 보다 오버헤드가 적다.
그리고 튜플의 크기가 20 이하인 경우 GC 되지 않고 나중을 위해 캐싱되는 경우가 있다.
즉, 같은 크기의 튜플이 필요해지면 OS 에 메모리 할당을 요청하지 않고 캐싱한 공간을 사용한다.
그렇기 때문에 가변성이 필요 없는 경우 Tuple 사용하는 것은 리스트에 비해 엄청난 이점이 있다.
만약 사용할 데이터의 프로퍼티와 값이 불변이라면 네임드 튜플이 좋은 선택이 될 수 있다.
>>> from collections import namedtuple
>>> Point = namedtuple('Point', 'x y')
>>> point = Point(x=1, y=2)
>>> point.x, point,y
(1, 2)
3-3 반복자 (Iterator)
반복자는 반복 가능한 자료형들을 실제로 탐색하는 객체다.
그래서 반복형은 반복하기 위해서 __iter__ 메소드를 통해 반복자 (Iterator) 를 반환한다.
그리고 반복자 객체는 __next__ 메소드에 다음 아이템을 가져오는 방법을 명시한다.
>>> s ='ABC'
>>> for char in s:
... print(char)
...
A
B
C
반복형 s 는 사실 내부적으로 반복자로 변환된다. for 문 대신 while 문을 이용해 직접 위의 과정을 흉내 내면 다음과 같다.
>>> s = 'ABC'
>>> it = iter(s)
>>> while True:
... try:
... print(next(it))
... except StopIteration:
... del it
... break
반복형에서 반복자를 it 를 생성하고 StopIteraion 이 발생할 때까지 반복한다.
(전문가를 위한 파이썬 14.2 의 예제다.)
당연하게도 Python 에서 제공하는 표준 시퀀스 객체들은 자체적으로 __iter__ 가 기술 되어 있기 때문에 여러분이 오픈소스를 할 때가 아니면 __iter__ 을 오버라이딩할 일은 아마 없을 것 같다.
사실 오픈소스에서도 __iter__ 를 오버라이딩해서 보면 딱히 대단한걸 하지는 않는다.
대부분은 이미 파이썬에서 제공된 반복형을 return iter(iterable) 감싸서 반환하는 정도다.
아니면, 아직 설명하진 않았지만 제네레이터를 구현할 뿐이다.
3-4 제네레이터 함수
제네레이터 함수는 함수가 반복자 같이 동작하게 해준다. 함수 본체에 yield 키워들 가진 함수는 모두 제네레이터 함수로 호출되면 제네레이터 객체를 반환한다.
>>> def gen_123():
... yield 1
... yield 2
... yield 3
...
>>> g = gen_123()
>>> next(g)
1
>>> next(g)
2
>>> next(g)
3
>>> next(g)
StopIteration error
>>> for i in gen_123():
... print(i)
...
1
2
3
next 를 호출할 때 마다 다음 yield 코드가 있는 곳으로 가서 아이템을 반환한다.
제네레이터의 놀라운 점은 무한히 아이템을 반환할 수 있으면서 메모리도 적게 사용할 수 있다는 점이다.
>>> def get_even_numbers():
... x = 2
... while True:
... yield x
... x += 2
...
>>> even_numbers = get_even_numbers()
>>> next(even_numbers)
2
>>> for i in even_numbers:
... print(i)
...
4
6
8
~ 무한히
메모리를 적게 사용하는 이유는 감각적으로 당연하게 받아들 일 수 있을 것 같지만 기술적으로 설명해 보겠다.
일단 반복자 (Iterator) 자체가 값을 느긋하게 (Lazy) 처리하도록 설계되어 있다.
느긋하게 라는건 그 값이 정말 필요할 때 가져오는 것인데 next(iterator) 는 한 번에 한 항목만 생성해 오기 때문에 느긋하다.
그리고 이전에 탐색한 값, 앞으로 탐색할 값에 대한 정보는 전혀 저장하지 않는다. 단지 현재 반복자가 어느 위치에 있는지만 기록할 뿐이다. 탐색할 값의 정보는 List 같은 반복형이 들고 있는 것이다.
근데 제네레이터는 이 값의 나열을 물리적인 메모리에 저장하는 게 아닌 논리적인 코드로 가지고 있다.
그래서 x 가 2 인 시점에 64 는 대한 값은 메모리에 없으며 반대로 x 가 64 일 때 2 라는 값은 메모리에 존재하지 않는다.
>>> list(get_even_numbers)
위의 코드는 저장할 값이 무한이기 때문에 끝나지 않는다. 그리고 OS 에 의해 종료된다.
Python2 에서 range 는 리스트를 반환하고 xrange 는 제네레이터를 반환하기 때문에 xrange 가 range 보다 훨씬 적은 메모리를 사용하고 속도도 빠르다. Python3 에선 range 가 xrange 기 때문에 xrange 가 없다.
4 Dict
사전 자료형은 애플리케이션에서 종종 사용되며 파이썬 구현의 핵심 부분이다.
내장 함수 저장, 객체 속성 관리, 함수 키워드 인수 등 내부 곳곳에 사전이 사용된다.
사전은 뛰어난 성능을 자랑하는데 뒷 배경에 해시 테이블이 있다.
먼저 해시 함수는 임의의 길이 데이터를 고정 길이 데이터로 매핑하는 함수다.
>>> hash('hello')
6686714520681537385
>>> hash('hello!')
5133168273725402504
>>> hash((0.1, 0.2))
-3333760149633600381
참고로 hash 내장 함수는 내장 자료형은 미리 정의된 알고리즘을 사용하고 사용자 정의 자료형의 경우는 __hash__ 메서드를 호출한다. 만약 사용자 정의 자료형이 __hash__ 메서드를 정의하지 않으면 기본적으로 id () 값을 이용해 해싱한다.
해시 테이블은 중간에 빈 항목을 가진 희소 배열이다. 해시 테이블의 항목을 종종 버킷이라고 한다.
사전에 키를 조회, 삽입, 삭제할 때 키의 버킷은 키의 해시값을 이용한 오프셋으로 결정된다.
해시값으로 오프셋을 결정하는 방법은 해시값 % 배열 크기, 해시값의 최하위 비트 사용 (비트 수는 배열의 크기에 따라) 등이 있다.
파이썬은 최하위 비트를 사용해 오프셋을 결정해 버킷을 선택한다.
버킷에는 해시값, 키에 대한 참조, 값에 대한 참조가 들어간다. 모든 버킷의 크기가 동일하므로 오프셋을 이용해 바로 버킷에 접근할 수 있다.
그래서 조회, 삽입, 삭제가 O(1) 만에 이뤄진다.
CPython 초기 버킷 결정 코드
i = hash & mask;
CPython 버킷 구조체
typedef struct {
/* Cached hash code of me_key. */
Py_hash_t me_hash;
PyObject *me_key;
PyObject *me_value;
} PyDictEntry;
Q. 버킷에 해시값과 키 참조가 저장되는 이유는?
이 질문에 대답하기 위해선 먼저 해시 충돌에 대해 알아야한다.
세상에 존재하는 무수히 많은 키를 고정 길이인 해시값으로 변환하기 (many-to-one 대응) 때문에 다른 두 개의 키에서 같은 해시값이 생길 수 있는데 이를 해시 충돌이라고 한다. 파이썬 기준 해시값이 달라도 하위 비트가 같으면 같은 버킷을 참조하게 되는데 이 또한 해시 충돌이라고 생각하면 된다.
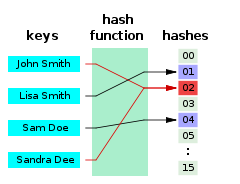
(위키 피디에서 발췌)
그렇기 때문에 해시 테이블은 반드시 해시 충돌을 극복해야한다.
접근 방식에 따라 체이닝 (Chaning) 과 오픈 어드레싱 (Open addressing) 로 나뉜다.
체이닝은 버킷에 들어갈 수 있는 엔트리 숫자에 제한을 두지 않는 방식이다.
버킷에 엔트리를 저장하는 방법은 링크드 리스트가 될 수도 있고 트리가 될 수도 있는데 구현 나름이다.
추가적인 메모리를 사용하기 때문에 파이썬은 오픈 어드레싱 을 사용한다.
체이닝과 달리 오픈 어드레싱은 버킷에 들어갈 수 있는 엔트리가 하나다.
그래서 충돌이 발생한 경우 다른 버킷을 선택하는 알고리즘이 필요하다.
선형 탐색, 제곱 탐색, 이중 해싱 알고리즘이 있다.
선형 탐색은 충돌이 발생한 경우 고정 폭을 옮긴 버킷을 사용하는 것이다. (보통 바로 다음 버킷)
이 알고리즘은 인접한 버킷들이 채워져 있는 경향을 유발하는데 이를 Primary Clustering 이라고 한다.
버킷들이 몰려 있는 경우 해시 충돌이 발생할 확률이 높기 때문에 성능 하락 가능성이 높다.
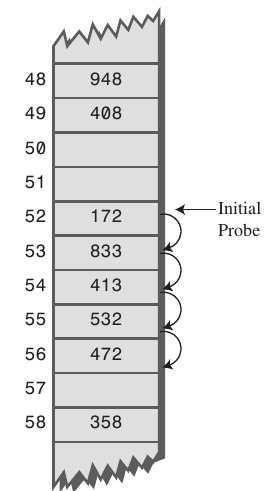
제곱 탐색은 버킷을 찾는 폭이 제곱수로 늘어난다.
x, x + 1, x + 4, x + 9, x + 16, …
제곱 탐색은 엔트리의 분포가 선형 탐색 보다 골고루 퍼지지만 초기 버킷 위치가 동일한 경우 같은 충돌이 발생한다.
엔트리는 인접하지 않아도 초기 버킷이 동일하면 연속적인 충돌이 발생하는 것을 Secondary Clustering 라고 한다.
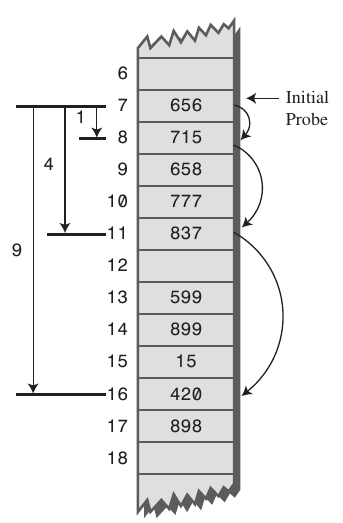
(stackoverflow 이미지 참조)
이중 해싱은 2 개의 해시 함수를 사용한다. 하나는 해시값을 얻기 위해 사용하고 다른 하나는 충돌이 발생했을 때 폭을 결정하기 위해 사용한다. 따라서 해시값이 같더라도 이동폭이 달라지고, 이동폭이 같더라도 최초 해시값은 다르기 때문에 primary, secondary clustering을 모두 완화된다.
체이닝은 메모리 오버헤드가 크기 때문에 파이썬은 오픈 어드레싱을 사용한다.
오픈 어드레싱 중에서도 선형 탐색의 변형을 사용한다.
간략히 코드로 표현하면 다음과 같다.
/* Starting slot */
slot = hash;
/* Initial perturbation value */
perturb = hash;
while (slot is full && slot->me_key != key)
{
slot = (5*slot) + 1 + perturb; /* slot & mask 로 배열에 접근하기 때문에 인덱스에 넘치치 않음 */
perturb >>= 5;
}
perturb 는 뒤흔다는 뜻인데 덕분에 해시값 마다 이동폭이 다를 수 있다.
쉬프트 연산을 하는 이유는 모든 hash 비트가 버킷을 찾는데 영향을 끼치기 위함이라고 한다.
하필 5를 쉬프트하는 이유는 경험에 의한 것으로 5일 때 해시 충돌이 적어졌다고 한다.
이런 측면 때문에 파이썬의 해시 충돌 해결법을 랜덤 탐색이라고 표현하는 경우도 있다.
흥미가 있다면 https://hg.python.org/cpython/file/52f68c95e025/Objects/dictobject.c 를 참고하자.
길었지만 이제 왜 버킷에 해시와 키 참조가 저장되는지 설명이 된거 같다.
다른 키지만 같은 버킷을 선택할 수도 있기 때문에 해시값과 키가 동일한지 확인이 필요하기 때문이다.
Q. 사전 키에는 어떤 것들이 올 수 있나?
해시 가능한 (hashable) 객체들만 사전의 키가 될 수 있다.
모든 객체는 0 과 1로 이뤄져 있기 때문에 모든 객체가 해시 가능하다고 생각된다.
그래서 나는 해시 테이블이 올바르게 동작하기 위해선 키가 갖춰야하는 조건이라고 말하는게 더 정확하다고 생각하지만 아무튼 그게 그 의미다.
조건은 다음과 같다.
- 수명 주기 동안 결코 변하지 않는 해시값을 가지고 있다.
- 해시값이 같은 객체는 동치성 (==)을 가져야한다.
지금까지 설명을 이해하면 저절로 왜 위의 조건을 충족시켜야 하는지 이해가 된다.
해시 테이블에 등록 되고 해시값이 바뀌면 해당 키를 찾을 수 없다.
해시값은 같은데 동치성이 다르면 해시 충돌이라고 인식하게 된다.
이런 이유로 파이썬 내장 불변형은 해시 가능하다.
하지만 불변형이 항상 해시 가능한 것은 아니다.
>>> d1 = {}
>>> d1[(1, 2)] = 'a'
>>> d1[([1, 2], [3, 4])] = 'b'
Traceback (most recent call last):
File "<input>", line 1, in <module>
TypeError: unhashable type: 'list'
불변형이 가변형을 포함할 수 있기 때문이다.
Q. 언제 해시 테이블의 크기가 커지는가?
해시 테이블은 속도를 위해 공간을 포기한 예다.
해시 테이블의 크기 (m), 저장된 키 개수 (n) 이라고 할 때 n/m 을 load factor 라고 하는데 테이블의 load factor 가 2/3 보다 작게 유지한다.
테이블의 크기가 바뀌면 최하위 비트도 바뀌기 때문에 버킷 결정 기준이 바뀐다.
그래서 키의 위치는 바뀔 수 있다.
python 3.6 부터 사전은 삽입 순서를 기록하는 OrderedDict 가 되었다.
추가로 배열을 하나 더 만들어서 순서를 기록하는 것이다.
그래서 사용자가 느끼기에 키 위치가 변하지 않는 것 처럼 느껴진다.
똑같이 해시 테이블을 사용하는 집합으로 이 사실을 할 수 있다.
>>> set1 = {'a', 'b', 'c', 'd'}
>>> set1.add('e)
>>> set1
{'b', 'd', 'a', 'c', 'e'}
참고로 Dict 의 기본 키기는 8 이다.
#define PyDict_MINSIZE 8
Q. 원소 삭제는 어떻게 이뤄질까?
먼저 알야할건 원소를 삭제한다고 단순히 버킷을 NULL 로 만들 수 없다는 점이다.
해시 충돌이 3 번 발생해 1번, 2번, 3번 버킷이 같은 해시값을 가진 원소로 이뤄져 있다고 가정하자. 여기서 2번 원소를 삭제해 NULL 로 만들면 어떤 일이 벌어질까?
3번을 찾기 위해선 1번, 2번에서 충돌이 발생해야 하는데 2번이 비어있기 때문에
읽기 요청이면 에러를 반환하고 쓰기 요청이면 2번 버킷에 값을 쓰게 된다.
그래서 파이썬은 NULL 대신에 Dummy 객체를 저장한다.
그렇게 하면 2번에서도 해시 충돌이 발생해 3번 버킷을 찾을 수 있게 된다.
그 상태에서 또 동일하게 해시 충돌이 발생하는 새로운 키에 쓰기 요청이 발생하면
4번 버킷이 아닌 Dummy 가 저장 돼있던 2번 버킷에 데이터를 쓴다.
Q. OrderedDict 가 큰 이점을 가지는 상황은 언제인가?
대표적으로 LRU 캐시가 있다. Least Recently Used Cache 의 약자로 캐시 공간이 부족해졌을 때 가장 오래전에 사용된 객체를 지우는 알고리즘이다.
OrderedDict 는 삽입된 키의 순서를 기록 하지만 가장 최근에 읽은 목록을 관리하지는 않는다. 근데 어떻게 LRU 캐시에 사용될 수 있을까?
방법은 간단한데 읽을 때 읽는 키를 삭제하고 다시 삽입하는 것이다.
그럼 가장 최근에 읽은 키는 리스트의 끝에 가장 오래전에 사용된 키는 리스트의 처음에 위치한다.
데이터 공간이 부족해지면 리스트의 처음을 삭제하면 되기 때문에 O(1) 에 가능해진다.
>>> @functools.lru_cache(maxsize=8)
>>> def get_user(user_id):
... call_api
... return user
>>> get_user( 1004)
user 1004
>>> get_user(1004)
user 1004 (without network call)
최대 8 개의 키를 캐싱하는 함수다. 9 번째 새로운 user_id 를 요청하면 가장 오래전에 사용된 키가 사라진다.
lru_cache 를 사용하는 함수의 인자는 해시 가능해야한다.
방금 말한 것 처럼 인자를 OrderedDict 의 키로 사용하기 때문이다. 저장하기 때문이다.
참조
- 고성능 파이썬
- 전문가를 위한 파이썬
- Operating System: Concepts
- Beautiful Code
- https://stackoverflow.com/questions/5201852/what-is-a-thread-really
- https://www.artima.com/weblogs/viewpost.jsp?thread=214235 (귀도 반 로섬 - GIL 을 없애는 것은 쉽지 않다.)
- https://www.geeksforgeeks.org/g-fact-57/ (원자성이란?)
- https://www.dabeaz.com/python/UnderstandingGIL.pdf
- https://stackoverflow.com/questions/27742285/what-is-primary-and-secondary-clustering-in-hash
- https://stackoverflow.com/questions/9010222/how-can-python-dict-have-multiple-keys-with-same-hash
- https://ratsgo.github.io/data%20structure&algorithm/2017/10/25/hash/